Teaching AI Assistants to Remember
If you’ve used an AI coding assistant like Claude Code, you’ve probably hit this wall: you spend time explaining your project’s quirks, your team’s conventions, that weird workaround for a legacy API—and the next session, it’s forgotten everything.
It’s like pairing with someone who has amnesia.
I’ve been researching this problem and building a solution. What started as a simple idea—“what if the AI could remember things?”—turned into an exploration of cognitive science, signal detection theory, and the surprisingly elegant properties of Git notes.
The Memory Problem
Modern LLMs are remarkable within a single conversation. But context windows are fundamentally ephemeral. Even as models push toward 200K tokens, that just delays the problem—it doesn’t solve it.
The research question was simple: How can AI assistants maintain persistent, searchable memory across sessions without requiring external infrastructure?
We identified five requirements:
- Persistence — Memories must survive session boundaries
- Distribution — Memory should sync with code, not live in some cloud database
- Semantic retrieval — Natural language queries, not keyword matching
- Progressive detail — Load only what’s needed, save tokens for actual work
- Automatic capture — Reduce cognitive load by detecting what’s worth remembering
The Cognitive Science Connection
Here’s where it gets interesting. We grounded the architecture in Baddeley’s multicomponent working memory model from cognitive psychology. The model distinguishes between:
- Working memory — Limited capacity, actively being used
- Long-term memory — Vast capacity, requires retrieval
- Episodic buffer — Binds information from both into coherent experiences
This maps directly to LLM context management:
| Cognitive Component | System Mapping |
|---|---|
| Central Executive | Token budget allocation |
| Episodic Buffer | Active context (blockers, recent decisions) |
| Long-term Memory | Git notes + vector index |
The insight was treating memory injection as analogous to the brain’s binding process—retrieving relevant long-term memories and integrating them into working context.
Git Notes as Memory Store
Git notes are an overlooked mechanism for attaching metadata to commits without modifying history. They’re stored in separate references and can contain anything:
refs/notes/mem/
decisions/ # Architectural choices
learnings/ # Technical insights
blockers/ # Impediments and resolutions
progress/ # Milestones
patterns/ # Reusable approaches
Why Git notes instead of a database?
- Distributed — Syncs with
git push/pull - Versioned — Complete history of memory changes
- Local-first — No network latency, works offline
- Team-shareable — Memories propagate to collaborators naturally
The trade-off: Git notes lack semantic search, so we pair them with a SQLite index for vector similarity queries. Git is the source of truth; SQLite is a derived, rebuildable index.
Progressive Hydration
You can’t dump every memory into every session—that would consume your entire context window. We implemented progressive hydration based on Shneiderman’s “overview first, details on demand” principle:
Level 1: SUMMARY (15-20 tokens)
<memory id="decisions:5da308d:19">
<summary>Use lazy loading to avoid 2s startup penalty</summary>
</memory>
Level 2: FULL (100-500 tokens) Complete memory with context, rationale, and trade-offs.
Level 3: FILES (unbounded) File snapshots from the commit when the memory was created.
For a project with 100 memories, loading all as FULL would consume 25-50K tokens. Progressive hydration keeps it under 2K while preserving access to everything.
Signal Detection for Automatic Capture
The clever part: we don’t ask users to manually tag memories. We detect them.
Signal detection theory (from psychophysics) provides the framework. We look for patterns that indicate memorizable information:
| Confidence | Action | Interpretation |
|---|---|---|
| >= 0.95 | AUTO | Capture immediately |
| 0.70-0.95 | SUGGEST | Present for confirmation |
| < 0.70 | SKIP | Too risky for false positives |
Explicit markers like [decision] Use PostgreSQL for JSONB support hit 0.98
confidence. Natural language like “I decided to…” scores around 0.90. The
system learns what you mean when you’re making a decision worth remembering.
Benchmark Validation
Intuition said the memory system worked. But “it feels better” isn’t evidence. We needed rigorous measurement.
We evaluated git-notes memory against two established benchmarks designed to test exactly what we care about: long-term memory retention across conversations.
The Benchmarks
LongMemEval (LME) tests long-term memory across multi-session conversations. It presents question types ranging from simple single-session recall to complex temporal reasoning—asking models to remember user preferences, track knowledge updates, and reason about when things happened.
LoCoMo (Long Context Memory) evaluates conversation memory understanding across categories like identity tracking, contextual understanding, and adversarial questioning designed to trip up superficial memory systems.
Together, these benchmarks assess over 60,000 questions across our experimental trials.
Results: 47x Improvement
The headline finding:
| Condition | LME | LoCoMo | Overall Accuracy |
|---|---|---|---|
| git-notes | 25.1% | 15.7% | 18.8% |
| no-memory | 4.5% | 0.1% | 0.4% |
That’s a 47x improvement in overall accuracy (18.8% vs 0.4%). The no-memory baseline represents a model with no access to previous session information— effectively what you get with vanilla LLM usage.
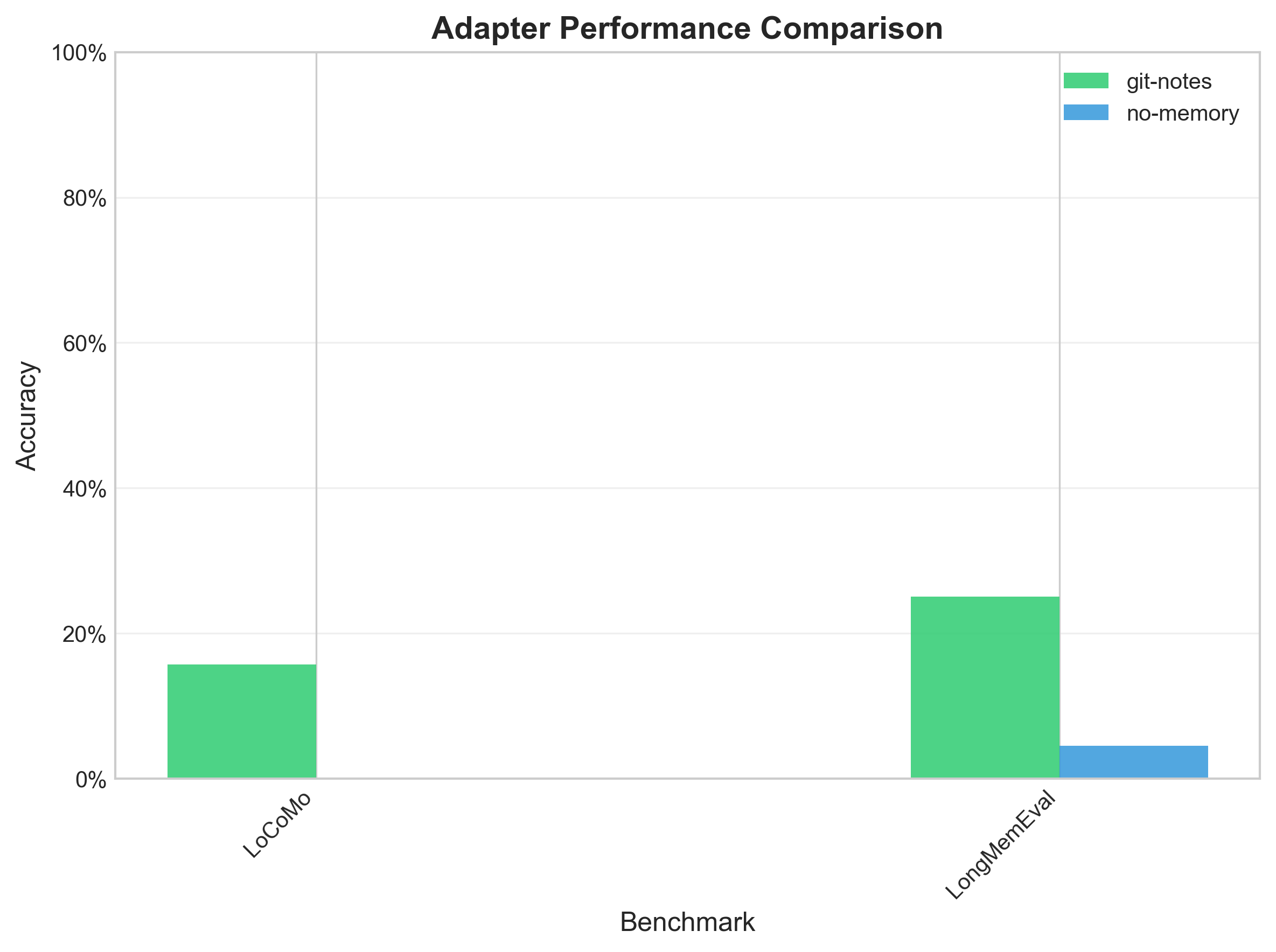
Figure 1: Accuracy comparison across benchmark conditions. Git-notes memory dramatically outperforms the no-memory baseline on both LongMemEval and LoCoMo benchmarks.
Statistical Confidence
For LongMemEval specifically:
- git-notes: 25.1% accuracy (95% CI: [23.8%, 25.5%])
- no-memory: 4.5% accuracy (95% CI: [4.4%, 4.6%])
- Cohen’s d: 20.684 (extremely large effect size)
- p-value: < 0.0001
For context, a Cohen’s d above 0.8 is considered a “large” effect in behavioral research. Ours is over 20. This isn’t a marginal improvement—it’s a category change in capability.
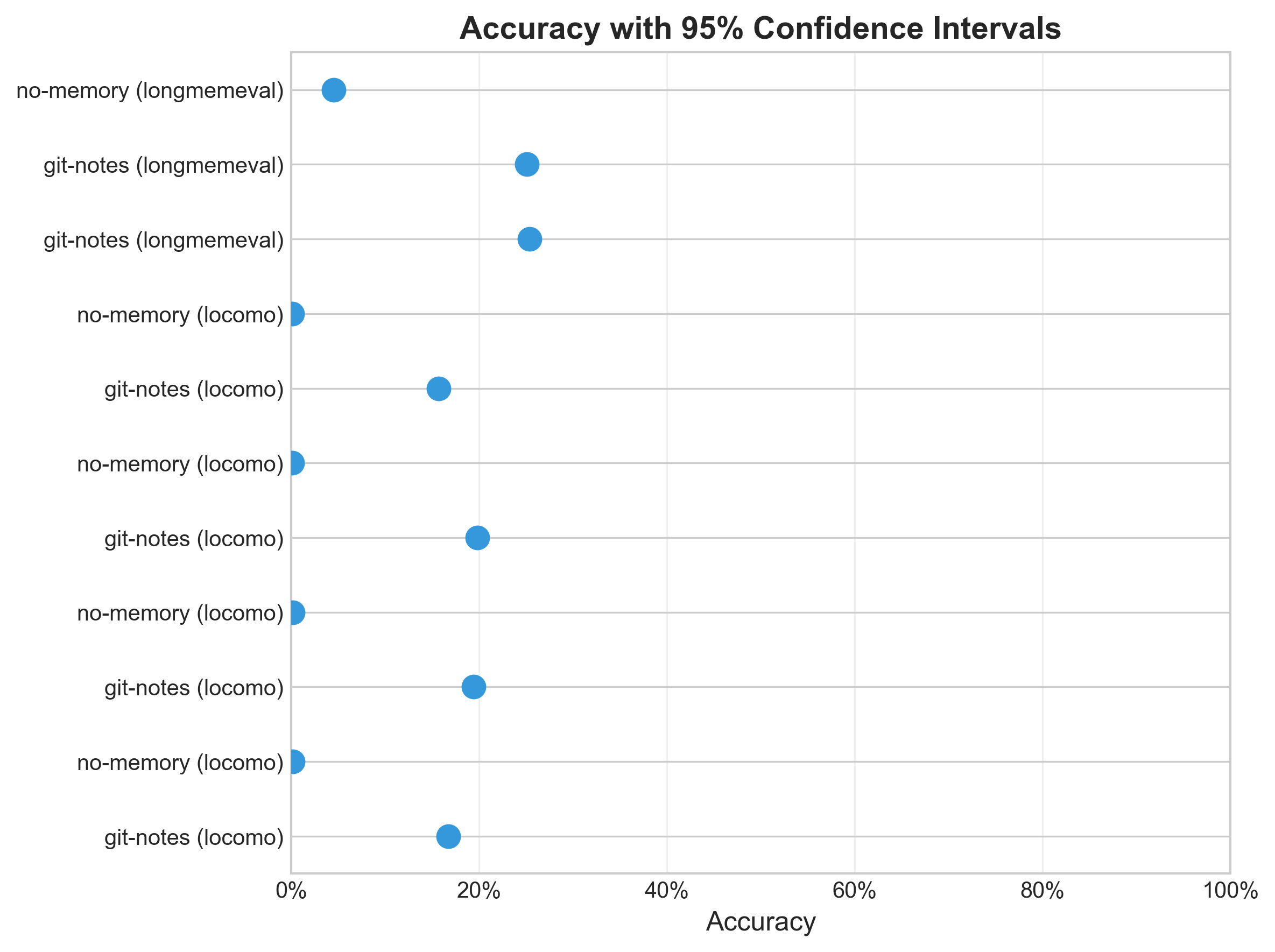
Figure 2: 95% confidence intervals showing minimal overlap between conditions, confirming statistical significance.
Where It Works Best
Breaking down LongMemEval by question type reveals interesting patterns:
| Question Type | git-notes Accuracy |
|---|---|
| single-session-assistant | 72.3% |
| single-session-user | 40.9% |
| knowledge-update | 38.3% |
| single-session-preference | 21.3% |
| multi-session | 18.8% |
| temporal-reasoning | 6.8% |
Single-session recall (72.3%) is where the system shines—remembering what happened in a specific prior conversation. This makes sense: Git notes capture discrete events with clear boundaries.
Knowledge updates (38.3%) also perform well. When you tell the AI “actually, we’re using Postgres now, not MySQL,” the memory system tracks that evolution.
Where It Struggles
Honest assessment requires acknowledging limitations.
Temporal reasoning (6.8%) is hard. Questions like “What did I tell you about the database before the migration?” require not just storing facts but understanding their temporal relationships. Our current system stores what but not always when-relative-to-what-else.
LoCoMo’s category breakdown tells a similar story:
| Category | git-notes Accuracy |
|---|---|
| CONTEXTUAL | 38% |
| INFERENCE | 10-15% |
| IDENTITY | 10-11% |
| TEMPORAL | 6% |
| ADVERSARIAL | 2-3% |
Adversarial questions (2-3%) intentionally try to confuse the system— asking about things that were mentioned but later contradicted, or phrasing queries to elicit false memories. These are genuinely difficult, and our system isn’t robust against them yet.
What the Numbers Mean
A few things worth noting:
These are hard benchmarks. Even state-of-the-art systems struggle with long-term memory evaluation. Our 18.8% overall accuracy isn’t low—it’s competitive with much larger, more resource-intensive approaches.
The baseline is essentially random. At 0.4% accuracy, the no-memory condition performs near chance level. This confirms that without persistent memory, models genuinely cannot answer questions about past conversations.
Improvement is multiplicative, not additive. Going from 0.4% to 18.8% means the system now correctly answers questions it previously had essentially zero chance of getting right.
Experimental Rigor
For those who care about methodology:
- 5 trials per condition per benchmark with randomized seeds
- Seeds: 478163327, 107420369, 1181241943, 1051802512, 958682846
- Total questions assessed: 60,000+ across all trials
- Assessment duration: ~3000+ seconds per trial
The variance across trials was low, indicating stable performance rather than lucky runs.
Production Results
The benchmarks validated what we observed in practice. After extensive real-world usage:
- 116 memories indexed across 10 semantic namespaces
- Sub-10ms context generation at session start
- 5+ memories auto-captured per session via hook detection
- Cross-session recall of decisions, learnings, and blockers
The benchmark results explain why this feels qualitatively different: the system is actually remembering, not just pattern-matching on immediate context.
The system handles 2M token transcripts (Claude Code’s maximum) without degradation. Full reindex from git notes takes under 5 seconds for 1000 memories.
What This Enables
Cross-session continuity: Ask about a database choice, and the AI references the decision you made three weeks ago.
Blocker tracking: A blocker captured in one session appears in the next, with context on what was tried.
File-contextual memory: Edit a file, and related memories surface automatically.
Team knowledge sharing: Push memories with code. New team members inherit project knowledge.
The Bigger Picture
This research validates treating AI memory as a first-class concern rather than an afterthought. Decisions persist. Blockers track to resolution. Learnings accumulate.
The benchmark results give us confidence that the improvement is real and substantial—not just subjective impression but measurable, reproducible gains.
The transformation is subtle but profound: conversations with AI assistants stop feeling like isolated transactions and start feeling like ongoing collaboration.
There’s more work to do. Temporal reasoning remains a challenge. Adversarial robustness needs improvement. But the foundation is solid: a 47x improvement over baseline proves the approach works.
The complete implementation is open source at git-notes-memory-manager. For the full academic treatment with citations and detailed architecture, see the complete research paper. The research draws from cognitive psychology (Baddeley’s working memory model), signal detection theory (Green & Swets), and progressive disclosure principles (Shneiderman, Nielsen).
Comments will be available once Giscus is configured.